Overview
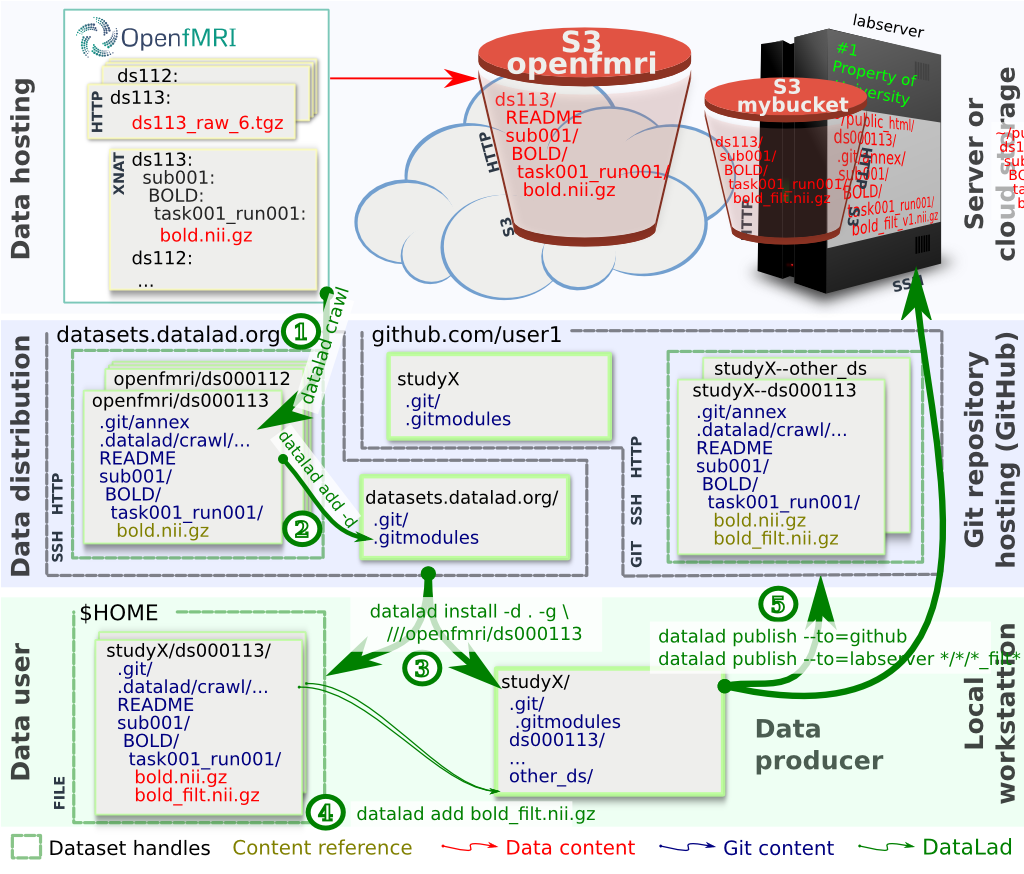
Prototypical life cycle of a hypothetical DataLad data distribution containing OpenfMRI datasets, which are available from both http://openfmri.org (as tarballs) and S3 AWS storage (extracted files):
- create dataset handles: large data content is referenced via meta-information on available data providers, maintained by Git-annex. The underlying git repository might not even contain actual content, but only content references;
- collate resulting dataset handles into a collection: a data distribution which would provide information about available datasets;
- use lean, locally installed dataset handles to obtain selected datasets with data content directly from original data providers (e.g., from S3 AWS storage and/or original archives);
- add new or derived data to a handle (bold_filt.nii.gz);
- publish individual or collections of updated dataset handles to a service like GitHub while copying only changed file content to e.g. a lab webserver (URL gets registered in the dataset handle) to make it publicly accessible.
Steps 1. and 2. only need to be carried out once for every dataset modification in an environment with full access to the actual dataset content. Subsequent runs of crawl command would pick up only changes (changed or new files, etc.) to create a new revision in the git/git-annex repository for the dataset, thus providing an automated monitoring and update service.
Timeline
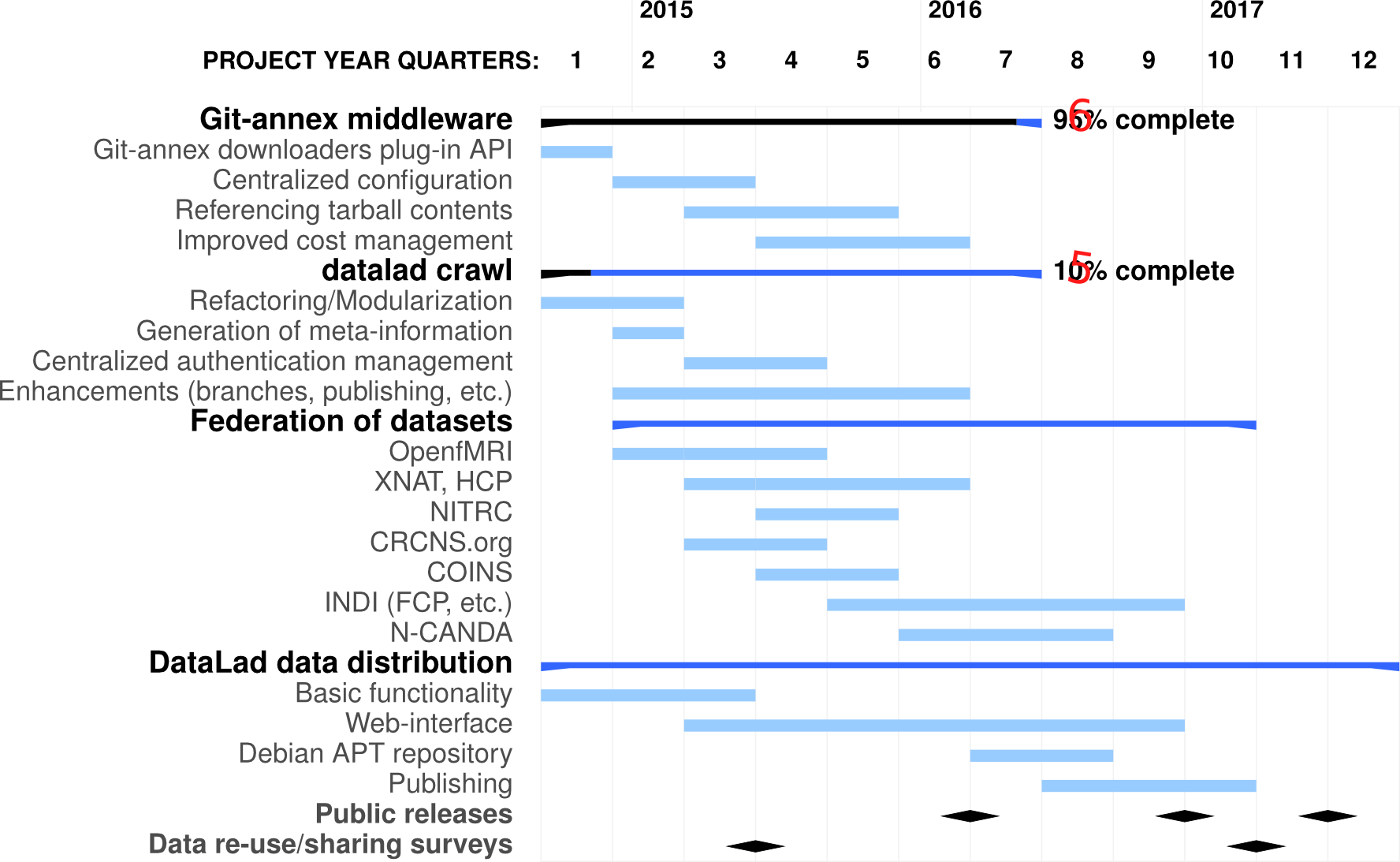
Activity duration indicators show periods of necessary developments leading to a first public release. Further stabilization efforts and feature additions will happen throughout the entire project duration depending on development progress of other sub-projects. For the first two groups, %-complete represents our assessment of the set of currently available features that are required for the proposed work.
Ongoing and future work
is happening in the open on http://github.com/datalad. Please use http://github.com/datalad/datalad.org to report problems with this website, or suggest improvements to it via issues or pull requests. http://github.com/datalad/datalad repository hosts the code for the main software portion of the project. Its issues page has convenience tags to group them. We will post some reports and notes about the progress of the project on this website's Articles page with tag development.